CC 51B : ARQUITECTURA DE COMPUTADORES
Tarea Nº 4
" Redes Neuronales con Arquitectura Paralela :
Arreglos Sistólicos "
Profesor
: Ricardo Baeza Y.Alumno
: Alejandro Alaff I.
" REDES NEURONALES CON ARQUITECTURA PARALELA :
ARREGLOS SISTÓLICOS "
Una red neuronal comprende varios elementos computacionales no-lineales (euronas) las que son unidas por una conección con peso. Neuroproceso es simple: Un nodo recibe la entrada, ejecuta la suma con peso, aplica una función de activación (usualmente de tipo sigmoid: sgm(x)= 1/1- EXP(-x) ) a la suma pesada, y las salidas resultan de otros nodos.
Y la sesión de neurosimulación consiste en dos fases: aprendizaje y llamado.
En la fase de aprendizaje, un conjunto de ejemplos entrenados es presentada a la red, y los pesos son ajustados de acuerdo con los valores de entrada, correlacionados, y a los valores de salida. En otras palabras una red aprende un problema. Esta fase es la más acotada computacionalmente
En la fase de llamado, un nuevo conjunto de entrada es presentada produciendo la red apropiados resultados.
El carácter de aprendizaje de las redes neuronales, las hacen atractivas para el reconocimiento de imágenes, discursos, caracteres, análisis de señales, sistemas de predicción, teoría de contol y robótica.
Ahora, el campo de las redes neuronales artificiales tienen un campo práctico de aplicación, gracias al auge de los métodos de simulación y neurohardware.
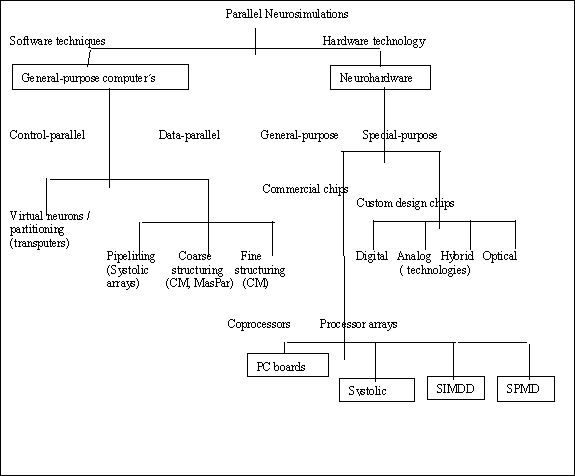
Aquí exploraremos: simulación paralela en propósitos computacionales generales, y simulación/emulación en neurohardware. Diferentes métodos de paralelización serán discutidos, junto con explicar las técnicas más populares. Como anticipo, veamos la siguiente figura: "Taxonomia de paralelización aproximada para neurosimulaciones":
Mientras el Sw parece acercarse a un modelo de programación óptima para el proceso neuronal, el Hw tiende a imitar el neuroparadigma usando lo mejor de la tecnología del silicon.
<<Indiquemos que la paralelización es necesaria para cubrir el alta demanda de neuroaplicaciones computacionales y de comunicación, pero el propósito general de máquinas paralelas es llegar pronto a las limitaciones de ejecución.>>.
Mencionaré ahora, de forma sintética, algunos de los aspectos más importantes ,sobre el tema en cuestión:
: instrucción sesión de paralelismo ->ejecución simultánea de diferentes sesiones.
: instrucción ejemplo de paralelismo ->aprendizaje simultáneo con diferentes ejemplos de instrucción.
: paralelismo de estrato ->ejecución concurrente de estratos sin una red.
: paralelismo de nodo ->ejecución paralela de nodos para una entrada simple.
: paralelismo de peso ->peso simultáneo en la suma sin un nodo.
Arquitecturas de computadores paralelos como posibles huéspedes para neurosimulaciones están caracterizados por varios y grandes procesadores organizados en diferentes topologías. Dependiendo de la presencia o ausencia de control central, los computadores paralelos pueden ser divididos en dos
claras categorías: Datos paralelos y Control paralelo. Donde, arquitecturas de Dato-paralelo procesan simultáneamente grandes conjuntos de datos usando un control de flujo centralizado (simple instrucción, múltiples datos) o regular (pipeline). Los huéspedes más populares en éste caso y para
simulaciones neuronales son Máquinas de Conección (CM), MasPar, Warp y arreglos sistólicos (systolic arrays).
Y , arquitecturas de Control-paralelo ejecutan procesos de forma descentralizada, manteniendo diferentes programas para ser ejecutados en diferentes procesadores (múltiples instrucciones, múltiples datos). Las dos categorías requieren diferentes estilos de programación. La elección de la arquitectura, correspondiendo a un esquema comunicacional, y a una técnica de paralelización puede afectar profundamente la performance., que mediría cómo decidir acerca la aplicabilidad de una neuroimplementación.
Y el propósito general del neurohardware puede ser subdividido en arreglos de procesos: arquitecturas complejas VLSI organizadas de manera dato-paralelo; y coprocesadores :son simples plataformas que pueden ser añadidas a estaciones de trabajo, convirtiendo estas máquinas en neurocomputadores.
" El neurocomputador del futuro puede consistir en varias componentes modulares recorriendo desde el hardware convencional a silicon altamente especializado, óptico, y artificio molecular. "
Ahora concentraremos nuestro estudio y análisis, a los procesos de arreglos, particularmente, a los arreglos sistólicos.
Como sabemos, corresponden a la descomposición de red neuronal para programación paralela. A una estructura de nodo por capa, se aplica pipeline para ser usado en arreglos sistólicos.
Así, estructurar vía pipeline es frecuentemente explotado en arreglos sistólicos –un hardware específico de una arquitectura diseñado para mapear un alto nivel de computación directamente en hardware.
Numerosos procesadores simples son concordados en un arreglo uni o multidimensional, ejecutando operaciones simples en manera pipeline. Computar vía sistólica puede también ser implementadas con propósito general máquinas paralelas ejecutando pipeline con un proceso rítmico.
Se ha usado enseñanza y capa en paralelismo para implementar una red de propagación de retroceso en un computador Warp con procesadores organizados bajo un anillo sistólico. En la fase siguiente, los valores de activación son shifteados circularmente a lo largo del anillo sistólico y multiplicadas por el peso correspondiente. Cada procesador acumula el peso parcial sumado. Cuando la suma ha sido evaluada, la función de activación es ejecutada.
Debido a la simplicidad de las neuronas y complejidad de los procesadores, mapear uno a uno ha resultado siempre en una pobre utilización de proceso y por encima una alta comunicación. Envasando más neuronas en un simple procesador es una estrategia mucho mejor. El mejor soporte arquitectural fue obtenido en arreglos sistólicos con comunicación circular. Con un proceso rítmico, incluso una estructuración de pipeline fino mejora la ejecución.
El paralelismo es alcanzado particionando el conjunto del modelo y ejecutando diferentes subconjuntos en diferentes procesadores independientes.
Se ha aplicado también, algoritmos sistólicos clásicos para la multiplicación matríz-por-vector para simulación de redes con propagación hacia atrás. Ellos explotan la paralelización de capa y nodo particionando cada capa de neuronas en grupos y cada operación en neuronas en la suma del producto de operaciones y la función nolineal.
Las fases hacia delante y hacia atrás son ejecutadas en paralelo vía pipeline un conjunto de múltiples entradas.
De las técnicas paralelas, tenemos por tanto, que para un computador de arquitectura de "arreglo sistólico" , su técnica estructural es Pipelined: (capa,nodo), el número de procesadores es 13K, el Benchmark es NETtalk, y el performance es de 248M (CUPS).
Así, la experiencia con computadores paralelos de propósito general han mostrado que arquitecturas dato-paralelo son más convenientes para proceso neuronal, dónde uno de los acercamientos dominantes corresponde a arreglos sistólicos. Por ejemplo, el sistema Synapse (producido por Siemens) es uno de los más populares neurocomputadores de propósito general, que está basado en una de arquitectura sistólica 2D diseñada para acelerar operaciones de matrices y búsqueda del máximo. Sus componentes básicas son chips de pipeline MA16.
Es decir, la ficha técnica es: Nombre del Producto=Synapse, Tecnología Arquitectónica=Sistólica, Técnica de Software=Pipeline, Capacidasd en Conecciones=Nulo, Performance=(CUPS:33M, CPS:5.12G).
Ampliando nuestro interés en las arquitecturas sistólicas, veamos la implementación de Redes Neuronales en la Arquitectura de Anillo Sistólico:
- Describiremos ahora las principales operaciones ejecutadas por los modelos de redes neuronales y describir como estas operaciones pueden ser ejecutadas en una arquitectura de anillo-conectado de procesamiento paralelo.
-Los modelos artificiales de redes neuronales varían significativamente en estructura y computación. Pero el principio básico de los modelos puede ser resumido en el empleo de una red con procesamiento simple de elementos llamados neuronas, interconectados vía eslabón de conección llamado sinapsis. Un importante futuro de las redes neuronales es su abilidad para aprender y modificar su conducta al variar su sus valores de interconección sináptica de acuerdo a un algoritmo específico de aprendizaje.
La operación de las neuronas en una red neuronal es formulada como una función de las entradas recibidas sobre las conecciones sinápticas y los varios parámetros locales de la neurona. La salida generada por la neurona i puede ser calculada como
![]() donde
donde
![]()
![]()
y ![]() es la función de transferencia de la neurona y
es la función de transferencia de la neurona y ![]() es el valor del bias.
es el valor del bias.
Además, en ésta ecuación ![]() representa el peso de suma de todas las entradas conectadas a la neurona i.
representa el peso de suma de todas las entradas conectadas a la neurona i.
La implementación de modelos de redes neuronales en arquitecturas de procesamiento paralelo requieren un método para mapear eficientemente cómputos neuronales para procesar elementos (PE) de la máquina elegida. En general, el objetivo de este mapeo es para distribuir los requerimientos computacionales entre los PE del sistema tal que la cantidad de comunicación interprocesos es minimizada y al mismo tiempo el número de PE ejecutando operaciones útiles (es decir tales operaciones que directamente contribuyen al procesamiento de redes neuronales) es maximizado.
Muchas aproximaciones para mapeo de redes neuronales en arquitecturas paralelas SIMD han sido propuestas.
La implementación de los requerimientos computacionales de datos locales de las neuronas, tal es la aplicación de la función de transferencia a la suma parcial de valores, que no requieren comunicación entre neuronas y puedan así ser procesadas eficientemente en paralelo indiferente de la comunicación interproceso de la red topológica.
Una simple estrategia de mapeo eficiente para implementar bloques de neuronas densamente conectados pueden ser inventadas por una asignación lineal de cada neurona a cada PE de un procesamiento en arreglo con conección de anillo. Como se aprecia en la siguiente figura:
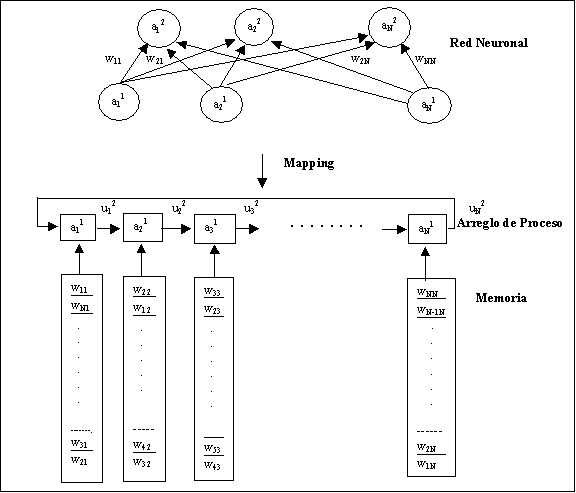
Figura: Mapeando una red neuronal conectada totalmente con un procesamiento en arreglo de anillo sistólico.
Por simplicidad, se ha supuesto que el número de procesadores en el sistema es mayor o igual al número de neuronas.
Considerando las ecuaciones dadas para la red neuronal, como el proceso de cálculo para la generación de resultados; en el mapeo considerado, sólo un simple ciclo sistólico para cada procesador es requerido para cada trayectoria para ejecutar la operación múltiple-acumulada, entonces múltiples trayectorias pueden utilizar el mismo PE cada uno a diferente tiempo. Ëste futuro concede para la ejecución en paralelo de varias trayectorias en la red.
La arquitectura de anillo sistólico es seleccionada en éste caso.
El mapeo de redes neuronales en procesamiento en arreglo de anillo-conección es altamente eficiente cuando el número de neuronas en la red es igual al número de procesadores en el procesamiento en arreglo.
Y explotamos todo el posible paralelismo en redes neuronales al tener un gran número de procesadores.
El número de ciclos requeridos para procesar una red neuronal usando el mapeo en una arquitectura de anillo sistólica es igual al número de ciclos requeridos para cruzar una trayectoria (haciendo un círculo completo a lo largo del anillo en procesamiento) más los ciclos adicionales usados para implementar la función de activación de neurona.
La implementación de redes neuronales de multicapas en un arreglo de anillo sistólico unidimensional (1-D) puede también ser ejecutado usando la técnica de mapeo descrita antes multiplexando el tiempo asociado a cada capa en el arreglo de proceso. La computación asociada para cada capa en la red neuronal puede ser ejecutada consecutivamente en el arreglo de anillo como el flujo de datos de la capa de entrada hacia la capa de salida, tomando un tiempo de ejecución de O( LP ), dónde L es el número de capas en la estructura de red neuronal, y P representa el número de PE en el arreglo en procesamiento. Pero, técnicas de pipeline pueden ser usadas para reducir el tiempo a O( P ) siendo L un arreglo de anillo organizado en una topología bidimensional (2-D).
Para una implementación eficiente, se puede asumir un igual número de neuronas en el mapeo para las diferentes capas, siendo una fuerte restricción en la interconección estructural de redes neuronales.
También podríamos considerar como red neuronal una red booleana de actualización paralela. Y ésta red consiste en un sistema dinámico y acoplado de ecuaciones booleanas de la forma
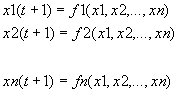
![]()
donde
Con esto podremos obtener redes con representación booleana incluso en 3-D, construyendo incluso clases de sistemas booleanos estables que pueden ser usados para una memoria asociativa de alta-ejecución. Y ésta memoria asociativa tiene las siguientes características: (1) garantiza almacenamiento para todas las memorias fundamentales; (2) control preciso para sobre la vasija de atracción para cada memoria fundamental; (3) no daña la memoria; (4)convergencia extremadamente rápida; y (5) previsión para un estado base.
Quedaría sí pendiente, un estudio de ésta estructuración de red y memoria con los arreglos sistólicos.
Bibliografía: