Este esquema es una extensión
de la cache de columnas asociativas.
Usa una búsqueda secuencial partiendo de la posición principal.
Aunque las posiciones no-principales son mucho menos importantes que las
principales, la forma en que la cache las búsca afecta significativamente
su performance. Por lo tanto, se usa un índice de búsqueda
para mejorar la eficiencia de la búsqueda.
Una posición en un set sólo
puede contener un acierto para una referencia si el bloque en la posición
es cargado desde la memoria principal en un fallo de una referencia previa
que tenía la misma posición principal que la actual referencia.
Nos referimos a estas posiciones como posiciones seleccionadas pertenecientes
a la posición principal correspondiente. Usamos una tabla índice
para mantener información sobre las posiciones seleccionadas. El
sistema de la cache usa esta tabla índice para encontrar las direcciones
de posiciones que examinará y para ignorar aquellas direcciones
que no pueden contener un acierto.
 La
dirección de una posición seleccionada tiene dos partes:
los n' bits mayores son el número del banco, y los c-n'
bits menores son la dirección relativa del bloque dentro del banco.
El sistema de la cache deriva la dirección relativa del bloque dentro
del banco directamente desde los c-n' bits menores de x,
y genera el número del banco usando la información de la
tabla índice durante la búsqueda.
La
dirección de una posición seleccionada tiene dos partes:
los n' bits mayores son el número del banco, y los c-n'
bits menores son la dirección relativa del bloque dentro del banco.
El sistema de la cache deriva la dirección relativa del bloque dentro
del banco directamente desde los c-n' bits menores de x,
y genera el número del banco usando la información de la
tabla índice durante la búsqueda.
En la tabla índice, destinamos un vector de bits de largo n
para cada posición, cada bit corresponde a una posición en
el set. El valor de un bit en el vector indica si la posición
correspondiente es una posición seleccionada (excepto la posición
principal). Para soportar una rápida modificación de la tabla
índice, concatenamos todos los vectores de bits para las posiciones
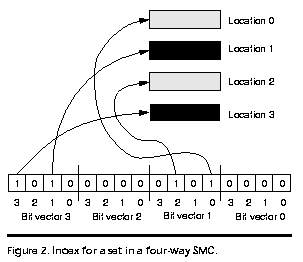
en el set en un item. La figura 2 muestra el índice para
un set en una cache multicolumna secuencial 4-asociativa. En esta
figura, el vector de bits i (i=0, 1, 2, 3) es el índice
para la posición i, el bit j (j=0, 1, 2, 3)
en unnvector de bots corresponde a la jth posición en el
set, y un 1 en el bit indica que la posición correspondiente
es una posición seleccionada. El índice en la figura 2 da
la siguiente información:
-
Para referencias cuya posición principal es 1, hay dos posiciones
seleccionadas: 0 y 2.
-
Para referencias cuya posición principal es 3, 1 es la unica posición
seleccionada (hay un 1 en el bit 3 del vector de bits 3, pero la posición
3 es la posición principal).
-
Para referencias cuya posicone principal es 0 o 2, no hay posiciones seleccionadas.
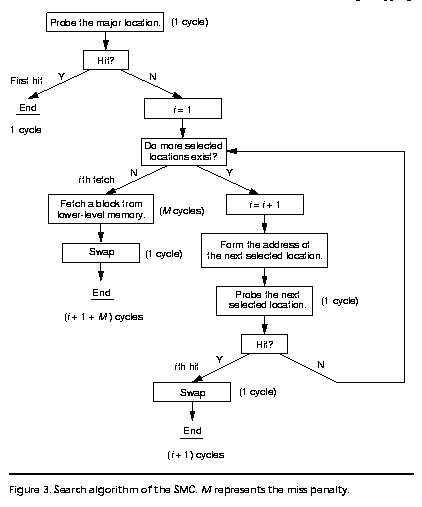 La
figura 3 muestra el algoritmo de búsqueda para este esquema. En
una referencia, la búsqueda examina la posición principal.
Al mismo tiempo, el sistema de la cache lee la información del índice
sobre el correspondiente set en la tabla índice y la usa
para formar la dirección de la siguiente posición seleccionada.
Si la primera prueba es una falla, el sistema examina la siguiente posición
seleccionada mientras genera la dirección de la siguiente posición
seleccionada, usando nuevamente la información del índice.
Este proceso continua hasta que se produce un acierto o hasta que se han
examinado todas las posiciones seleccionadas, en cuyo caso el sistema trae
un bloque desde la memoria principal. Cada prueba requiere un ciclo. Cada
prueba requiere un ciclo. Para un acierto no en el primer intento o una
falla, un swap es necesario para mover el nuevo bloque MRU a la posición
principal para la referencia actual.
La
figura 3 muestra el algoritmo de búsqueda para este esquema. En
una referencia, la búsqueda examina la posición principal.
Al mismo tiempo, el sistema de la cache lee la información del índice
sobre el correspondiente set en la tabla índice y la usa
para formar la dirección de la siguiente posición seleccionada.
Si la primera prueba es una falla, el sistema examina la siguiente posición
seleccionada mientras genera la dirección de la siguiente posición
seleccionada, usando nuevamente la información del índice.
Este proceso continua hasta que se produce un acierto o hasta que se han
examinado todas las posiciones seleccionadas, en cuyo caso el sistema trae
un bloque desde la memoria principal. Cada prueba requiere un ciclo. Cada
prueba requiere un ciclo. Para un acierto no en el primer intento o una
falla, un swap es necesario para mover el nuevo bloque MRU a la posición
principal para la referencia actual.