1. Introducción
2. Parámetros de la cache
de instrucciones.
3. Optimizaciones y transformación
de código.
3.1 Base
de la optimización.
3.2 Perfil
de ejecución.
3.3
Colocación de Instrucciones.
3.4 Expansión
de funciones en línea.
3.5
Procesos Superescalares.
4. Experimentos y análisis.
5. Conclusiones.
1. Introducción.
El compilador juega un rol protagónico en el rendimiento de los procesadores, pues son estos los que traducen el código de alto nivel a lo que podríamos llamar un código de máquina hecho a mano. Clásicamente los compiladores reducen el número de instrucciones, sin embargo esto limita la eficiencia de la optimización. Para dar un ejemplo un programa que tenga un cuerpo pequeño y funciones que realizan las tareas nos da una pequeña una pequeña área de acción para realizar optimizaciones, para esto el método de expansión de funciones en línea reemplaza las llamadas a funciones por el código de ésta, con ello tenemos un área de acción más extensa para realizar las optimizaciones. Estas optimizaciones incrementan la cantidad de líneas de código para aumentar la eficiencia. Por lo tanto vemos claramente que estas optimizaciones deben tener un efecto sobre el rendimiento de la cache.
A continuación se revisan los efectos de las optimizaciones de expansión de código sobre distintos rangos de configuraciones de cache de código. Los datos experimentales indican que tales optimizaciones reflejan una fuerte y no intuitiva implicancia sobre el diseño de la cache de instrucciones.
Se estudian los efectos tres tipos de optimizaciones de expansión de código : colocación de instrucciones, expansiones de funciones en línea y optimizaciones superescalares. La primera reduce la razón de pérdida en cache pequeñas, la segunda mejora el rendimiento en cache pequeñas, pero decrece en cache de tamaño medio y la tercera incrementa la razón e pérdida en cache pequeña, sin embargo, incrementa la secuencialidad de instrucciones de acceso por lo que un simple esquema de carga avanzada cancela los efectos negativos. Por último se mostrará que los tres tipos de optimizaciones mejoran el rendimiento de pequeñas cache en cargas consecutivas.
Volver
2. Parámetros de la cache de instrucciones.
Las dimensiones de la cache son expresadas por 3 parámetros :
Volver
3. Optimizaciones y transformación de código.
3.1 Base de la optimización.
El compilador utilizado es un compilador de C. Éste utiliza
en set de optimizaciones estándar disponibles en muchos compiladores.
El objetivo de las optimizaciones es reducir una aplicación e su
tiempo de ejecución. Las optimizaciones locales son realizadas
dentro de un bloque de instrucciones, mientras que una optimización
global es realizada a través de los diferentes bloques básicos
del programa.
3.2 Perfil de ejecución.
El perfil de ejecución es medido en su rendimiento a través
de mediciones de Benchmarks. Los programas son traducidos a C para
ser compilados y ejecutados. Los perfiles de información son
recogidos usando un programa con un promedio de 20 entradas por benchmark.
Cada entrada adicional es utilizada para medir el rendimiento de la cache.
3.3 Colocación de Instrucciones.
Reordena el programa para mejorar el rendimiento de la memoria. Este método mejora el rendimento de la cache realizando un orden jerárquico de las instrucciones. El algoritmo trata de eliminar los conflictos de mapeo a la cache e incrementa el uso de la memoria en forma secuencial.
Para una función dada se toman muchos pasos para guardar la secuencia de instrucciones. Para cada función los bloques básicos, que tienden a ser ejecutados en forma secuencial, son agrupados en trazos. Los trazos son la unidad básica utilizada para la colocación de instrucciones. Se reordenan los trazos, insertando los trazos que menos han sido ejecutados.
Esto puede incrementar la necesidad de agrandar el tamaño de
los bloques de la cache. Para el mismo tamaño de cache, un
incremento en el tamaño del bloque decrementa la cantidad de TAGs
a guardar.
3.4 Expansión de funciones en línea.
Consiste en reemplazar las llamadas a funciones que más se utilizan
por el código de este. Esto es bueno para agrandar el área
de acción para la optimización.
Esta transformación aumenta el número de referencias
únicas, por lo resultan más pérdidas.
Sin embargo la tasa de pérdidas decrece, pues sin la expansión
existe un potencial de reemplazo de llamada en las funciones alojadas en
la cache de instrucciones.
3.5 Procesos Superescalares.
El proceso superescalar se utiliza en computadores con procesadores multiescalares y consta de 4 partes :
Formación de superbloques : Un superbloque es una secuencia de instrucciones que pueden ser alcanzadas sólo desde la parte de arriba y puede contener míltiples ramificaciones con más instrucciones. Cuando la ejecución alcanza un superbloque es como si todos los bloques básicos dentro del superbloque fueran ejecutados. Un trazo puede ser convertido en un superbloque creando una copia del trazo y redireccionando todas las transferencias de control en el medio del trazo de la copia.
Loop desenrollado : El cuerpo de un superbloque con loop es duplicado para incrementar la cantidad de instrucciones dentro del superbloque. Al desenrollar un loop N veces, el tamaño del cuerpo del loop se ve incrementado N-1 veces.
Loop Peeling : Hay veces en que los loop iteran muy pocas veces, por lo que el Loop desenrollado no son muy efectivos. Por lo tanto lo que se realiza es tomar el código como una línea recta sin necesidad de interpretrarlo como un loop.
Expansion de Branch Target : La colocación de instrucciones y la formación de superbloques introduce ramificación de código. El branch target ayuda a eliminar el número de ramificaciones tomadas por la copia de traget de bloques básicos.
Volver
4. Experimentos y análisis.
Se realizó in benchmark con programas de las siguientes características:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Los tamaños de cache considerados para las pruebas fueron de 1 a 256 K bytes y el tamaño de los bloques fue de 12, 32, 64 y 128 bytes.
En esta parte de considera la siguiente notación :
no : sin optimización.
pl : colocación de código.
in : función en línea.
su : soptimización superescalar.
Los aumentos de código con los diferentes métodos se muestran
en la siguiente tabla
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
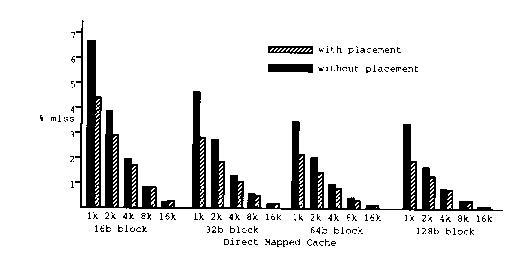
La figura 1 muestra el efecto promedio de la colocación de instrucciones sobre el porcentaje de pérdida de la cache. Por un lado se reduce la razón de pérdida en cache pequeña 1 a 2 K, se puede comparar que una cache de 1K con colocación de instrucciones se puede comparar a una cache de 2K sin ella. Pero en cache grande el efecto es poco notorio (8 a 16K).
 |
|
|
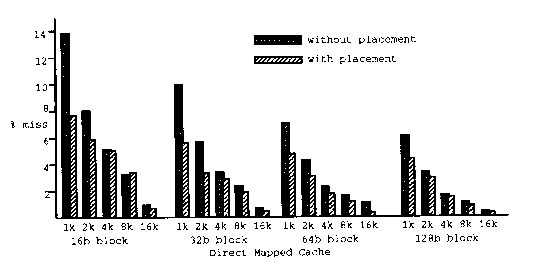
La figura 2 muestra cache con razones de pérdidad muy altas a
las cuales se les aplica la colocación de código. Como
se ve claramente el beneficio de la colocación de instrucciones
es más notorio aún.
 |
|
|
Volver
5. Conclusiones.
Se analizaron los efectos de las optimizaciones de expansión de código en tiempo de compilación sobre el diseño de la cache de instrucciones. Se mostró en primera instancia que tanto el método de instrucción en el lugar, la funciones en línea y las expansiones superescalares incrementaban de manera significativa la cantidad de líneas de código de un programa, por lo que el rendimiento de la cache se vería afectado, así como también el tamaño de esta debería ser significativo. Luego se mostró el efecto de cada método sobre la cache.
Para cache pequeña, donde la razón de pedida es considerable, la colocación de instrucciones reduce el número de referencias perdidas, pero aumenta el uso de bytes de transferencia por cada pérdida de la cache. Para cache grande el efecto no es notorio.
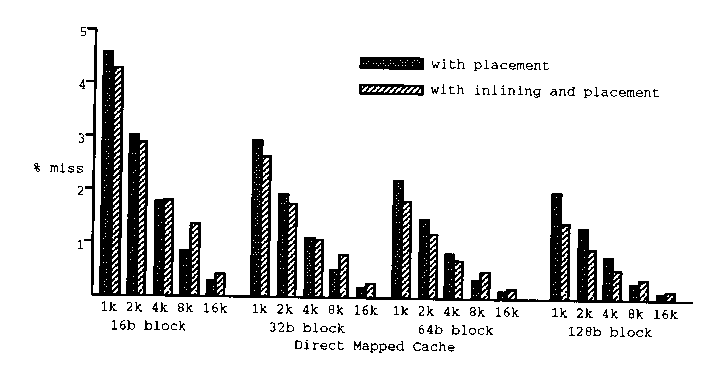
El método de función en línea afecta el rendimiento de la cache. Para cache pequeña ayuda a mejorar la secuencialidad, reduciendo la razón de pérdida. Para cache grande el efecto de reducir la razón de pérdida es pequeño.
El método superescalar también reduce la razón de pérdida. Incrementa la secuencialidad de instrucciones de acceso.
Los tres métodos mejoran el rendimiento en cache pequeña.