El CAT Cache
El CAT Cache consiste en área de datos, tag pointers y tag cache. La organización del área de datos es la misma que en las caches existentes. El tag pointers asociado con cada línea del área de datos sirve como link a un tag en el tag cache. El tag cache mantiene direcciones de tags distintas. Se espera que el tamaño el tag cache sea muy pequeño, alrededor de 8 a 32 entradas. Por cada línea en el área de datos hay a lo más un tag en el tag cache que le corresponde. Sin embargo, un tag en el tag cache puede corresponder a una o varias líneas en el área de datos.
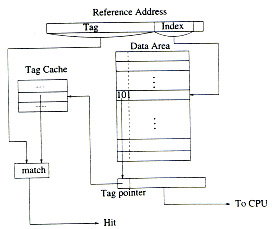
En la figura 1, muestra un diagrama con una posible implementación de CAT cache.
- Operaciones en el CAT Cache
- Ideas de Implementación
- Partial CAT Cache
- Parallel CAT Cache
- Set – Asociative CAT Cache
Cache Hits: Sobre una referencia a memoria, el campo index de la dirección de referencia localiza el dato en el área de datos y su correspondiente tag pointer. Este dato inmediatamente cargado en el buffer y se deja habilitado para la CPU. Cuando la parte tag de la dirección de referencia esta disponible, usualmente después de la traducción de direcciones, se compara con el tag, en el tag cache, apuntado por el tag pointer. Si ocurre un match, entonces ocurrió un cache hit. El tiempo del hit en el CAT cache es el mismo que en los caches comunes. Si no se necesita la traducir la parte del tag, entonces el tag cache puede ser accesado en forma paralela.
Cache Misses: Cuando el tag de la dirección de referencia no produce un match con el tag apuntado por el tag pointer, entonces se produce un cache miss. Se debe iniciar un acceso a memoria para traer el dato perdido. Durante el tiempo de esta operación, el tag de la dirección de referencia se compara con todos los tags del tag cache. Si el tag está presente, entonces no se necesita ingresarlo al tag cache, solo es necesario actualizar el tag pointer con la dirección del tag en el tag cache (tag merging).
Si el tag de la dirección de referencia no está en el tag cache, entonces ocurre un tag cache miss. Por lo que se debe ingresar el nuevo tag al tag cache. Si el tag cache no esta lleno, entonces se ingresa el nuevo tag en alguna entrada libre, si no, se inicia algún algoritmo de reemplazo sobre el tag cache. En cualquier caso, cuando se trae una nueva línea al cache, el campo del tag pointer debe ser actualizado con la dirección en la cual se almacenó el nuevo tag en el tag cache. Todas estas operaciones dentro del CAT cache se realizan en forma simultanea con el acceso a memoria. Entonces el cache miss permanece invariable comparado con los caches comunes.
Reemplazo de Tags: Si el tag cache está lleno cuando ocurre un tag cache miss, se necesita ejecutar una operación de reemplazo de tags. Una de las políticas de reemplazo más conocidas es el algoritmo LRU. Es importante notar que, en el tag cache, el reemplazo de un tag debe estar acompañado por un proceso que invalide todas las líneas del área de datos que están asociadas al tag que se va a reemplazar. Esta invalidación es necesaria para asegurar el buen funcionamiento del programa.
Cuando es necesario sacar un tag del tag cache, el hardware debe invalidar las líneas de cache asociadas a ese tag. En un cache write-through, solamente se limpian los valid bits (bits de validación) de las líneas afectadas. Esto se hace comparando el tag pointer con la dirección del tag que se esta eliminando y luego se limpian los valid bits correspondientes. Como el tag cache es pequeño, el número de bits en el tag pointer es entre 3 y 5. La celda CAM de nueve transistores puede ser usada para limpiar los correspondientes valid bits.
Política de Reemplazo del Menor Contador: Debido que se deben invalidar líneas en el cache para asegurar el buen funcionamiento de un programa, es posible que algunos datos que se usan frecuentemente sean invalidados erróneamente.
Para minimizar estos errores, se utiliza un contador de pocos bits para cada tag en el tag cache. El contador se incrementa cada vez que se ejecuta un tag merging, se decrementa cada vez que una línea de dato cuyo tag pointer apunta al tag es reemplazada en el área de datos. Cuando el tag se reemplaza en el tag cache, el contador se resetea a 0. Entonces, el valor del contador de un tag, refleja relevancia significativa de ese tag.
Si ocurre un tag cache miss, se reemplaza el tag que tiene el mínimo valor del contador. Tal política de reemplazo se conoce como least counter replacement (LCR).
Esta política se usa junto a la de LRU, ya que LCR no toma en cuenta la localidad temporal de los datos.
Existe un trade-off entre el costo de implementar tales contadores y la ganancia de desempeño. Para implementar el contador preciso, se necesitan log(número de líneas de cache) bits, sin embargo, en la práctica un par de bits es suficiente.
Una vez terminados los experimentos (se describen luego), se observó que solo una pequeña parte de los tags cambia frecuentemente. Para reducir el tamaño del tag cache y explotar la localidad de direcciones aún más, se considera particionar el campo de tag en dos partes: bits de mayor orden y bits de menor orden. Solamente los bits mayores se almacenan en el tag cache, mientras que los bits menores se almacenan junto a los datos. Este tipo de organización se llama Partial CAT Cache (ParCAT).
La figura 2 muestra un diagrama de un diseño de ParCAT.
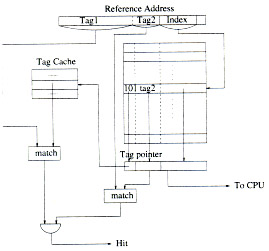
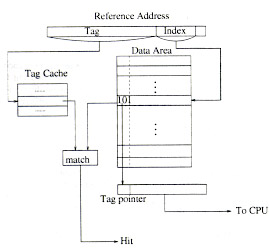
En este tipo de organización, el tag cache y el área de datos son accesados en paralelo. Se realiza una búsqueda asociativa en el tag cache y la decodificación del índex del arreglo de datos son hechos en paralelo. La dirección del tag en el tag cache y el tag pointer se comparan para determinar un hit o un miss cache. Ya que el tag cache tiene muy pocas entradas y esta organizado como un arreglo CAM, el tiempo de búsqueda en el tag cache queda oculto por el tiempo que demora la decodificación y chequeo de bits validos sobre el arreglo de datos. Por lo tanto, el Parallel CAT Cache, tiene el mismo tiempo que un cache con mapeo directo.
La figura 3 muestra un diagrama de un diseño de Parallel CAT cache.
Un n-way set-asociative cache consiste usualmente en n bancos de caches idénticos. Para implementar el CAT cache, cada uno de los n-way set associative cache puede ser organizado como un CAT cache. Para cada requerimiento, los n caches son accesados en paralelo. El campo índex activará n líneas del cache, mientras que el campo tag es enviado a los n tag caches, para encontrarlo. Si ocurre un match, entonces se produjo un hit, si no, se produce un miss. Hay que notar que solo una línea del cache puede ser encontrada en la búsqueda paralela de los n caches. Si ocurre un miss, se ejecuta un algoritmo de reemplazo para seleccionar el banco en el cual realizar el reemplazo. Si se cambia un tag dentro de un cierto banco, entonces solo se invalidan las líneas de cache que están dentro de ese banco, ya que la relación entre línea y tag solo esta confinada dentro del banco.
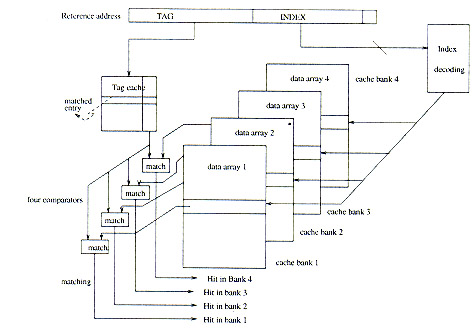
La figura 4 muestra un diseño de un 4-way set associative CAT Cache, con una configuración de n-tag n-cat
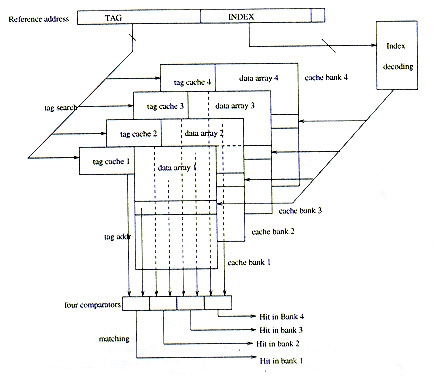
Por otro parte, la asociación entre el arreglo de datos y el arreglo de tags, puede ser definida globalmente. Esto significa, tener un tag cache global en el cual los tag pueden estar relacionados a múltiples líneas de datos en diferentes bancos de cache. El acceso es el mismo que se describió anteriormente, excepto a que el tag se envía al tag cache global. La dirección encontrada se compara con los n tag pointers de los n bancos de cache.
Con este diseño, reemplazar un tag del tag cache global afectará múltiples líneas de diferentes bancos.
La figura 5 muestra un diseño de un 4-way set associative CAT Cache, con una configuración de one-tag n-cat
Back | Menú Principal | Metodología de Simulación